Deed Dish is a tool for exploring property ownership in Chicago using data from the Cook County Recorder’s office. The goal of this project is to make data on current and historical property ownership accessible and transparent. Deed Dish is available at deeddish.com.
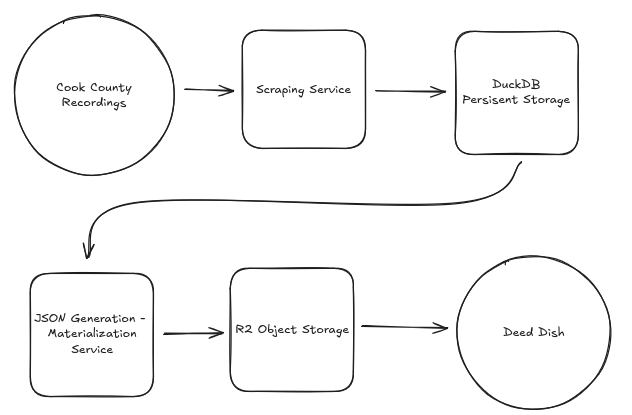
Deed Dish is composed of the following components:
The stack was built with a simple staged batch ETL pattern to keep the system simple and easy to maintain as a solo project.
The ingestion process is the system’s batch layer and web scraping service. Built in Python, the ingestion process scrapes and validates data using BeautifulSoup, structlog, and a sqlalchemy ORM model. After validation the data is loaded onto the database for storage and processing. The scraping service is hosted on GitHub.
Data is loaded onto a DuckDB instance for local processing and persistent storage. DuckDB was chosen for its speed, since the materialization pipeline runs multiple complex queries per document in the database. This use case was a great fit for an OLAP system instead of an OLTP system like Postgres which was tested during development and documented in more detail in another blog post.
The materialization pipeline is a Python service that generates documents for parcels and owners. Parcel-level documents contain the deed history for a given parcel, and owner-level documents contain a list of all parcel IDs with the owner in the deed history. Each document is stored as a single JSON file, with the final step of the pipeline transferring the document to a Cloudflare R2 bucket.
Alongside the parcel and owner documents, the materialization pipeline also generates a PMTiles file that serves as the visualization layer for the application. This file is generated using tippecanoe, taking the geometry definitions of parcels provided by Cook County as an input. This file is stored on the R2 bucket.
Document files are stored on a Cloudflare R2 bucket and accessed via HTTP requests to the Deed Dish CDN subdomain. Early in development I had planned to have the user interface run queries against the database directly, and I may eventually pivot back to that, but during development I ultimately made the decision to use R2 object storage because of cost and speed.
The user interface was built with Typescript, HTML, and CSS and uses Maplibre GL JS to render the interactive map and vector tiles in the browser. The application loads the PMTiles file into memory, and when the user clicks on a parcel on the map the CDN is queried, returning the parcel’s document and rendering the deed history in the browser. Visualizing ownership networks is done using a similar approach. When an owner’s name shows up on more than one deed, their name is displayed as a hyperlink that will query the CDN for the parcel ID values to highlight.
Hosting is handled using GitHub Pages, a free service provided by GitHub for hosting static sites. The repository can be found here
The Cook County Recordings website does not provide a clean representation of parcel data. Some parcels don’t have associated documents and some document pages have incomplete data. This was addressed using an ORM, robust logging using structlog to diagnose specific failure modes, and updates to the web scraping logic to handle missing values and align scraped outputs with the data model.
Initially my plan was to host the database and have the user interface run queries against it, but the size of my database (~7 million records) and relative complexity of the queries necessary for the interface meant that a simple hosted Postgres instance would be slow or costly. To address this challenge I chose to not expose the database to the client and instead generate materialized views for each parcel and keep them in persistent storage on a Cloudflare R2 instance.